
My research
What is the goal of BO?
Bayesian Optimisation (BO), as the name implies, is a method for optimisation, i.e. solving a problem of the following form:
\[\max_{x \in \mathcal{X}} f(x)\]where $\mathcal{X}$ is some set of “allowed” inputs to the function $f(\cdot)$. However, contrary to standard optimisation techniques, BO can optimise function $f(\cdot)$ without having to know anything about it! We only assume we can query the function $f(\cdot)$ at a selected point $x$, but we are only allowed a limited number of queries, as they are very costly and/or time-consuming. This problem setup, called black-box optimisation, is very difficult, but at the same time, ubiquitous, as we will show below.
Why do we need BO?
It turns out that there are numerous tasks that can be framed as a black-box optimisation problem and solved with BO! Examples include:
- Antibody design, where $x$ is a sequence of proteins and $f(x)$ is the efficiency of resulting antibody in fighting a pathogen (its binding specificity)
- Logic circuit design, where $x$ is the sequence of operations on the circuit and $f(x)$ is its quality, which is high whenever the circuit is small and fast
- Hyperparameter tuning, where $x$ is the hyperparameter of an algorithm and $f(x)$ is its speed or performance. For example, BO was used to tune hyperparameters of the famous AlphaGo algorithm
As you can see, this kind of problem setup appears in multiple domains across computer science, engineering and medicine! We can also see that in most of these problems (especially Antibody design) each evaluation of a proposed solution will take time and resources. As such, we need to be very sample-efficient! Fortunately, BO can do that! Let us have a look at how this is achieved next.
How does BO work?
As we do not know the function formula, we are unable to analytically find an optimum of our function. At the same time, we are also unable to differentiate the function $f(\cdot)$, which rules out the usage of gradient methods. What else can we try then?
In Bayesian Optimisation, we first look at the points, at which we have already evaluated the function. We use this knowledge to construct a surrogate model of the function, as shown below:
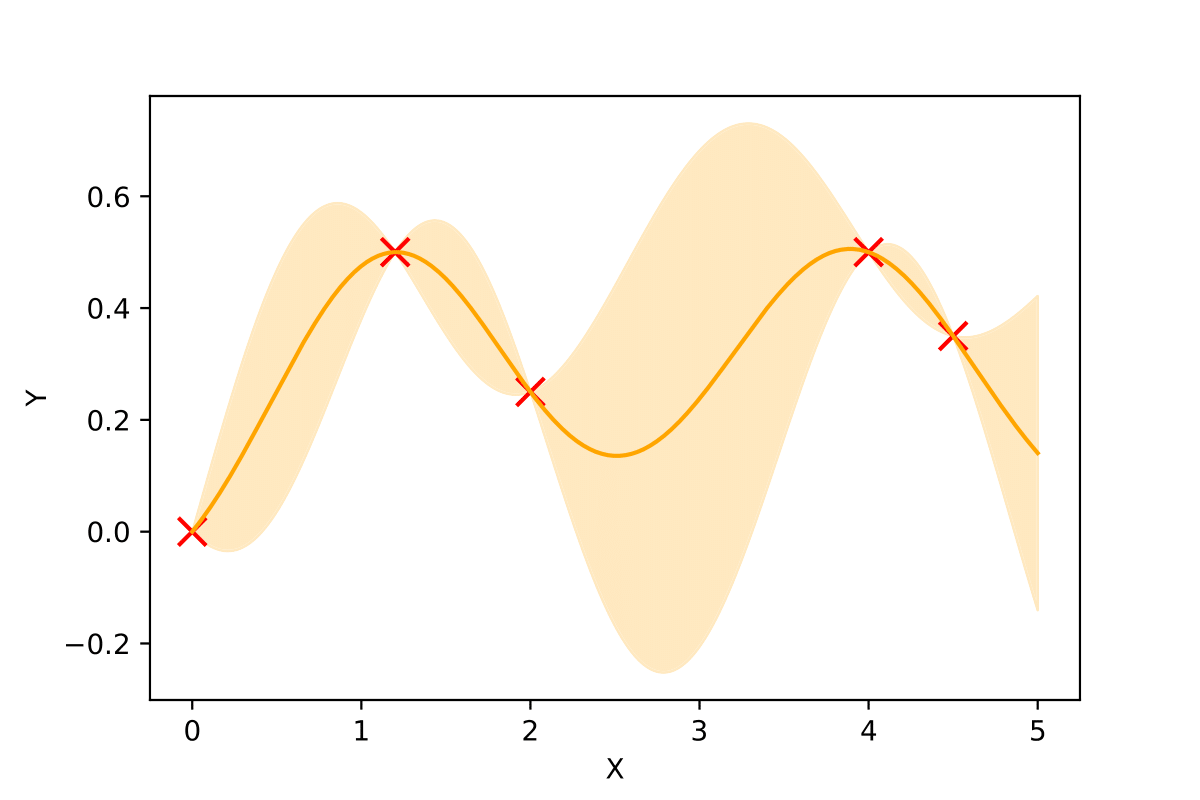
Here, we have 5 points, based on which we construct a model of the function (solid line) and compute its uncertainty (shaded regions). In the example above, we have used a surrogate model called Gaussian Process.
Given this model, we can now select the most promising point to try next! Usually, we want to try a point that has a large extrapolated value, but at the same time, we want to explore regions with high uncertainty to learn more about the function. A criterion that balances those two requirements is called an acquisition function. Given the model of the function $\mu(\cdot)$ and its uncertainty $\sigma(\cdot)$, a popular acquisition function called UCB, takes the form of
\[\alpha(x) = \mu(x) + \beta \sigma(x)\]where $\beta$ is the so-called exploration bonus, telling us how important it is for us to explore regions with high uncertainty.
We select the next point to try by maximising the acquisition function $x_{\textrm{new}} = \max_{x \in \mathcal{X}} \alpha(x)$. We then evaluate our function $y_{\textrm{new}} = f(x_{\textrm{new}})$ and with this new knowledge, we fit the surrogate model again, and select the next points to try. We repeat this process until we run reach a limit of function evaluations or when our best solution so far is already good enough.
More reading
You can have a look here for a more comprehensive tutorial on BO. If you would like to know more mathematical details about this procedure, have a look here.